






解密DeepSeek-V3推理网络:MoE架构如何重构低时延、高吞吐需求?
DeepSeek-V3发布推动分布式推理网络架构升级,MoE模型引入大规模专家并行通信,推理流量特征显著变化,Decode阶段对网络时度敏感。网络需保障低时延与高吞吐,通过端网协同负载均衡与拥塞控制技术优化性能。高效运维实现故障快速定位与业务高可用,单轨双平面与Shuffle多平面组网方案在低成本下满足高性能推理需求,为大规模MoE模型部署提供核心网络支撑。






一、推理场景和MoE模型引入网络新诉求
2025年初,DeepSeek-V3发布,迅速引发国内外的广泛关注和部署热潮。作为核心基础设施之一,分布式推理网面临全新的需求。整体来看,推理与训练的流量差异、MoE模型架构的引入以及DeepSeek开源技术方案等多重因素,影响了网络建设的方向和要求。
传统稠密模型的训练与推理流量中,95%以上为Tensor Parallel(TP)通信,主要在机内高带宽域通过all-reduce完成,机外低带宽域仅在同号卡间执行低流量的数据并行(DP)和流水线并行(PP)通信。而DeepSeek采用的MoE(Mixture of Experts)模型架构显著改变了流量特征。训练和推理阶段均不采用TP通信,取而代之的是大规模专家并行(EP)通信,训练阶段EP流量占比超过95%,推理阶段则达到100%。EP通信跨越多个高低带宽域,且采用all-to-all通信模式,通信结构复杂且流量巨大,对网络性能提出了更高、更差异化的要求。
DeepSeek模型参数规模达到6710亿,在推理部署中引入了PD分离和大规模EP并行,推动满血版高性能推理走向分布式。相比传统单机推理,分布式推理带来了显著差异,使得推理流量模式与分布式训练更为接近,但两者在流量特征上依然存在明显区别。
通信流量可由以下公式估算:(minibatch大小 × 上下文长度 × 隐藏层维度)× 节点数 × (dispatch_alltoall通信次数 × FP8字节数 + combine_alltoall通信次数 × BF16字节数)× GPU负责的层数。下表统计主要EP流量作为参考。
| 总通信量 | 单次通信量 | |
| 训练 | 315GB |
dispatch:112MB combine:224MB |
| 推理Prefill | 57.09GB |
dispatch:168MB combine:336MB |
| 推理Decode | 1218MB |
dispatch:3.5MB combine:7MB |
训练场景流量模式固定且明确,单次迭代总流量高达315GB,单次EP通信流量约112MB。
推理场景流量受用户输入影响,波动较大。Prefill阶段以4K上下文、batch size为4计算流量大小,单次迭代总流量约57.09GB,单次通信流量与训练相近;Decode阶段以128并发计算,单次迭代流量显著降低至约1.2GB,单次通信流量仅为几MB,Prefill与Decode阶段流量差异明显。
基于以上全新且复杂的网络需求,深入识别和分析DeepSeek推理网络的关键技术,是保障推理高性能、低成本与高可靠性的关键。下文我们将从低网络时延、高效网络运维和低成本组网角度,展开介绍DeepSeek推理网络关键技术。
二、低时延网络助力推理高吞吐
根据上述流量分析,Decode阶段的单次通信流量仅为3.5MB/7MB。结合DeepSeek官方开源通信库DeepEP的性能,当前场景下Decode阶段的dispatch通信时长在100us内,combine通信时长在200us内。Decode阶段的SLO通常要求低于50ms,但EP通信次数高达116次,每次通信都会导致时延叠加,因此对网络时延提出了很高的要求。综上,在Decode阶段,很少的单次通信流量、很短的通信时长、很高的SLO要求都对网络提出了较低的时延需求。
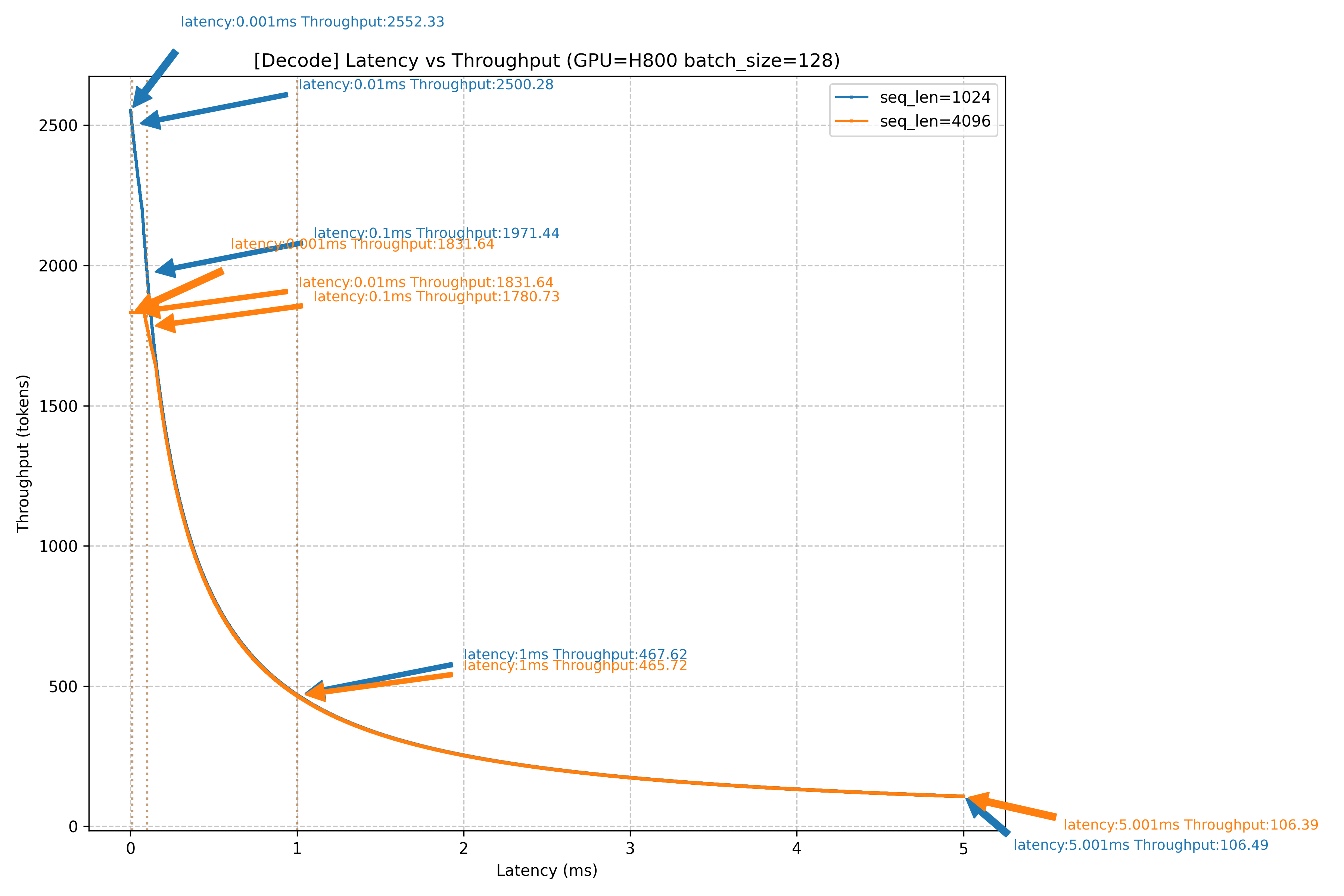
H800网络时延对Decode吞吐的影响
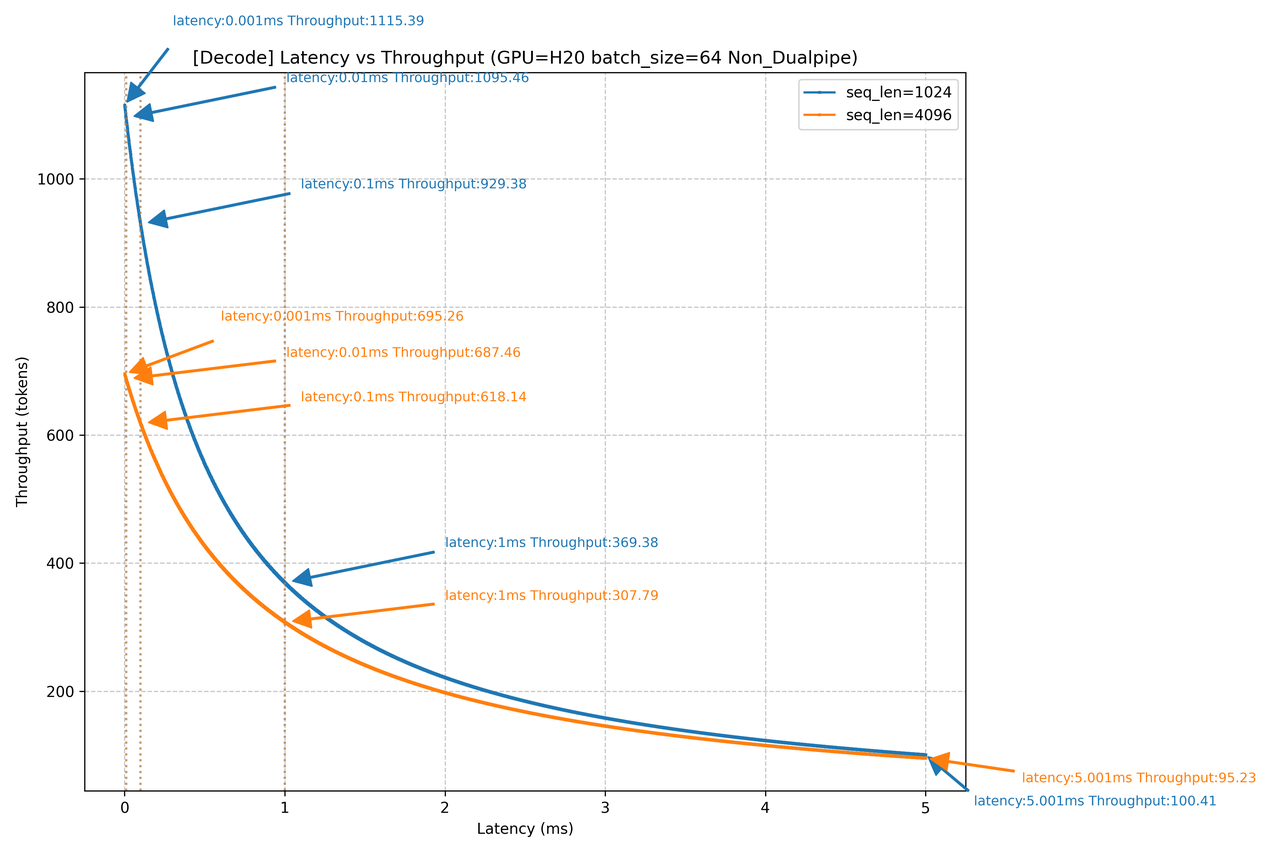
H20网络时延对Decode吞吐的影响
上图是对4K/1K上下文,1K输出的Decode场景,在H800/H20设备下,以128 batch作为场景,进行的网络时延对Decode吞吐影响仿真。如图所示,当网络侧产生1ms的时延增加时,无论是H800还是H20,在不同的上下文场景下,吞吐都会产生巨大影响,吞吐下降幅度高达80%左右,几乎已经直接导致当前Decode节点不可用。当网络上产生100us的时延时,4K上下文场景下,吞吐下降可能达到20%+。由此可见,Decode节点对网络时延的敏感度很高。在DeepSeek大规模EP并行all-to-all通信模式下,网络时延的主要影响因素是负载均衡和拥塞控制:
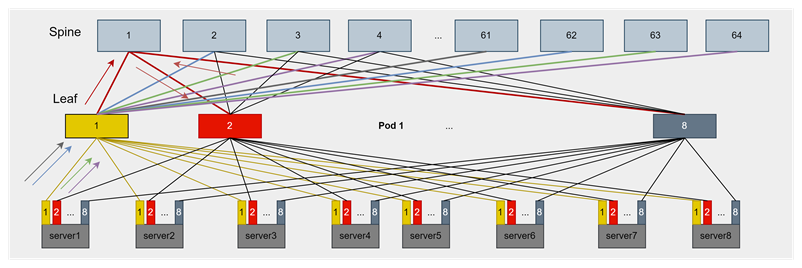
如上图所示,在大规模EP的DeepSeek推理场景,EP域的通信可能横跨多个Leaf,流量走向Spine,容易产生典型的ECMP哈希不均问题,导致较高动态时延。且DeepSeek的MoE模型推理易产生实例间负载不一致和实例内专家负载不一致问题,在网络上表现为流量中大小流混合。该现象更容易加剧ECMP不均导致的动态时延问题,不佳的负载均衡策略,在网络上容易引入100us+甚至更高的动态时延。如上文分析,这样的动态时延水平对吞吐的影响可能达到20%+。在DeepSeek官方场景中,采用IB交换机和CX网卡的Adaptive Routing(AR)技术,有效缓解了ECMP负载不均问题。在RoCE环境下,端网协同的负载均衡方案在如此苛刻的低时延要求下,是至关重要的。
此外,MoE模型的大规模专家并行通信本质上是一种all-to-all模式,网络中天然存在incast流量。合理的拥塞控制策略能够避免因流量降速或PFC(Priority Flow Control)触发而带来的高动态时延,保障网络时延的稳定性和推理性能。
三、高效端网运维保障高可用推理业务
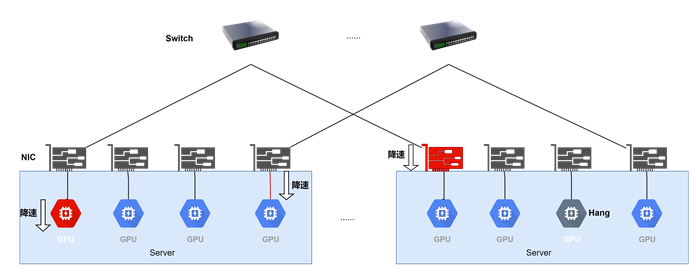
慢故障、hang异常
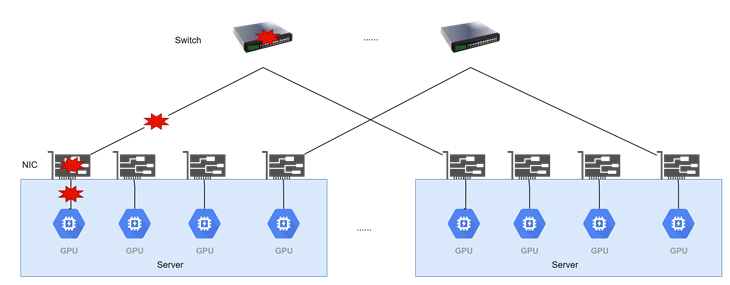
链路故障
随着DeepSeek推理引入大规模专家并行(EP),分布式推理集群面临与训练集群类似的故障挑战。根据Meta公开的研究数据,以1024卡集群为例,平均每7.9小时会发生一次故障。结合故障对推理的影响,可将故障类型归纳为三类:
慢节点异常:故障发生后推理任务不中断,但部分节点或阶段性能下降,导致整体推理被拖慢,表现为慢节点效应。
Hang异常:故障导致推理长时间卡顿于某一阶段,任务无法继续推进,但整体推理仍未中断。
链路故障:链路中断直接导致整个推理实例退出。
在慢节点异常和短时间Hang异常场景下,虽然推理任务仍在运行,但推理性能显著受损,TTFT(Time To First Token)和TPOT(Time Per Output Token)指标明显恶化,吞吐量可能下降50%以上。因此,针对慢故障和Hang异常的实时监控、快速定位与排查,对于保障推理性能具有重要价值。
而在长时间Hang异常或链路故障导致推理实例直接退出的情况下,业务影响更为严重。对于大规模实例部署环境,可通过请求快速切换至其他健康实例,虽可能牺牲部分用户体验,但能保障业务连续性。相较之下,少量实例部署(如单个Decode实例)发生故障时,往往直接导致业务中断,严重影响稳定性和用户体验。因此小规模场景下,故障的定位、逃生和规避,是保障业务可用性的关键手段。
四、高性价比推理组网压榨百万token成本
1.双口网卡双平面组网:
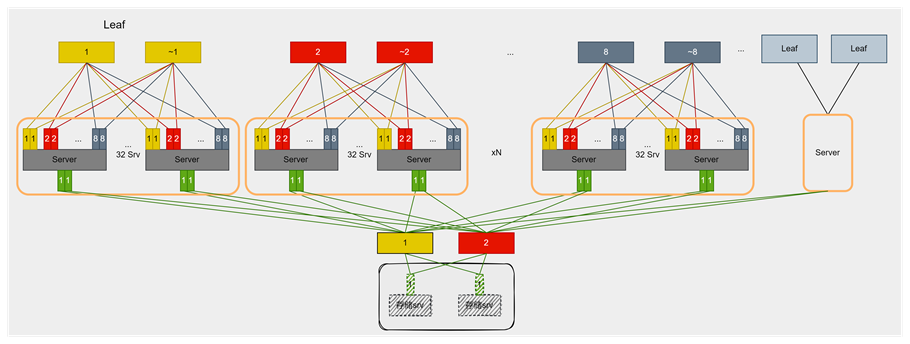
单轨双平面组网
基于上述对网络低时延和高可靠性的需求,采用如图所示的单轨双平面组网方案,能够最大程度保障性能与可靠性。相比传统CLOS架构,该方案在性价比方面更具优势。具体特点如下:
优势:
网络结构简洁:流量集中于Leaf交换机,降低跨交换机通信复杂度,显著减少时延。
成本效益高:支持铜缆互联,减少交换机数量,整体网络投入更低。
时延低:数据面链路最长仅为2跳,最大跳数为1跳,确保低时延传输。
流控需求低:无负载均衡问题,流量走单一路径,简化流控设计。
易于扩展:新增节点无需增加二层网络,支持集群横向扩展。
Bond适配性强:采用bond双平面组网提升网络可靠性,且由于无二层组网,bond方案不会带来额外交换机成本。
劣势:
灵活性受限:Prefill或Decode实例不可跨Leaf部署,单实例最大规模受限于256卡。
兼容性不足:组网针对推理流量特性优化,难以兼容训练与推理一体化场景。
KV Cache传输依赖存储网:在采用PD分离部署时,如果存在跨Leaf的PD实例,则必须配备存储网络以支持KV Cache传输。
2.Shuffle多平面组网:
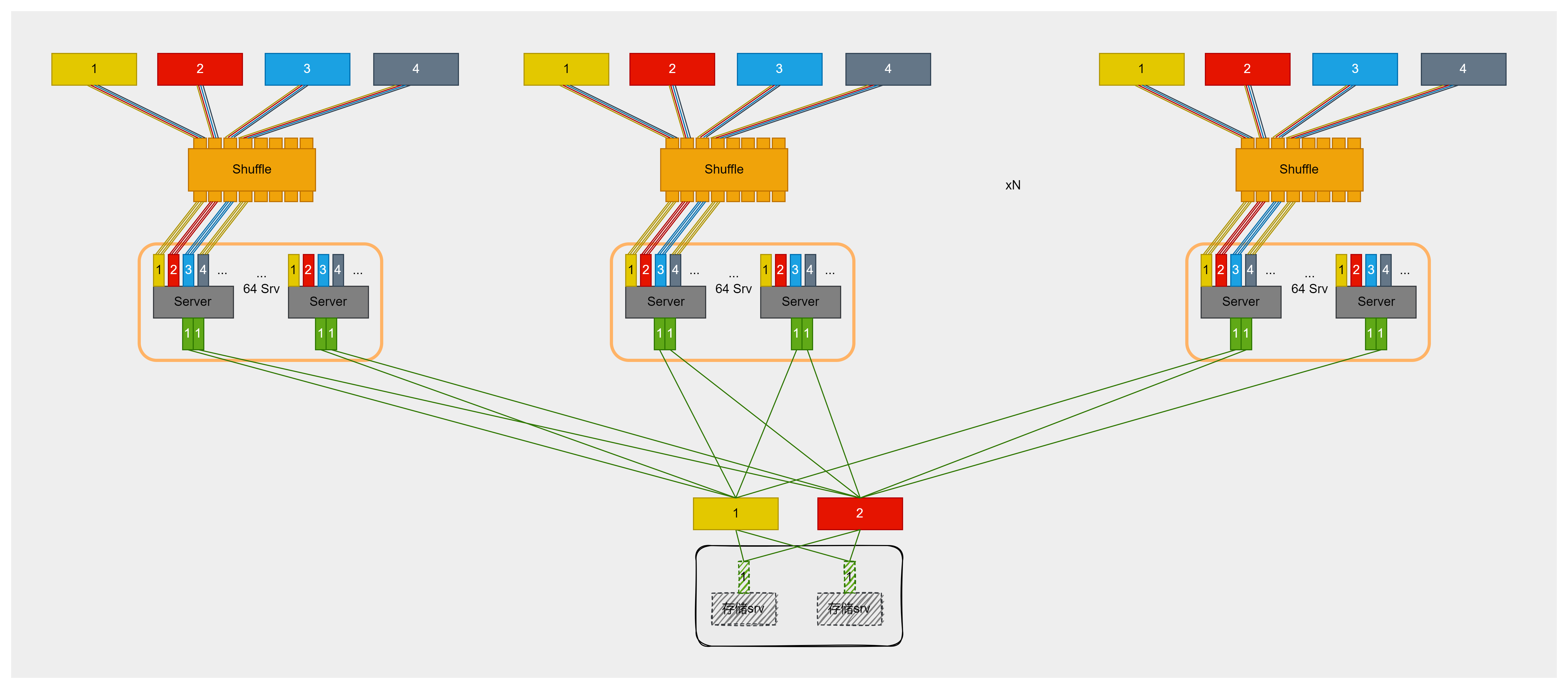
基于双网口网卡的双平面组网方案,单Pod最大规模受限于256卡,导致灵活性不足。为突破这一瓶颈,在Server与交换机之间引入Shuffle(光交叉盒),实现物理层面的分光。依托400Gbps网卡和TH5芯片交换机,组网方案升级为四平面,单Pod最大规模扩展至512卡,满足绝大多数推理部署需求。此方案支持更大规模的EP并行和PD实例数量增加,且PD实例无需跨Pod调度,大幅提升Pod内组网灵活性,显著降低对KV Cache存储网络的依赖。
未来,随着800Gbps网卡和TH6芯片交换机的应用,Shuffle多轨方案可拓展至8轨。在保证单GPU享有800Gbps带宽的前提下,单Pod最大规模可扩展至1024卡,满足超大规模推理服务需求。该方案在无二层组网架构下,依然提供很高的PD分离部署灵活性,PD实例无需跨Pod调度,也无需KV Cache传输专用网络,实现了卓越的性价比与性能。
总结
DeepSeek MoE模型的分布式推理部署带来了推理网络架构和性能保障的全新挑战。推理阶段的通信模式和流量特征与传统训练存在显著差异,尤其是Decode阶段对网络时延敏感,要求网络具备低时延和高吞吐能力。端网协同的负载均衡算法和拥塞控制技术是保障网络性能的关键。与此同时,推理业务高可用性要求完善的故障监控、快速定位和故障逃生策略。针对这些需求,设计简洁高效且具备高可靠性的单轨双平面组网方案,能够在保证性能的同时降低成本。未来,随着DeepSeek及类似大规模MoE模型的广泛部署,推理网络的优化和创新将成为核心竞争力。
相关标签:


点赞


更多技术博文
-

 高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团
高密场景无线网络新解法:锐捷Wi-Fi 7 AP 与 龙伯透镜天线正式成团锐捷网络在中国国际大学生创新大赛(2025)总决赛推出旗舰Wi-Fi 7无线AP RG-AP9520-RDX及龙伯透镜天线组合,针对高密场景实现零卡顿、低时延和高并发网络体验。该方案通过多档赋形天线和智能无线技术,有效解决干扰与覆盖问题,适用于场馆、办公等高密度环境,提供稳定可靠的无线网络解决方案。
-
#无线网
-
#Wi-Fi 7
-
#无线
-
#放装式AP
-
-
 打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布
打造“一云多用”的算力服务平台:锐捷高职教一朵云2.0解决方案发布锐捷高职教一朵云2.0解决方案帮助学校构建统一云桌面算力平台,支持教学、实训、科研和AI等全场景应用,实现一云多用。通过资源池化和智能调度,提升资源利用效率,降低运维成本,覆盖公共机房、专业实训、教师办公及AI教学等多场景需求,助力教育信息化从分散走向融合,推动规模化与个性化培养结合。
-
#云桌面
-
#高职教
-
-
 医院无线升级必看:“全院零漫游”六大谜题全解析
医院无线升级必看:“全院零漫游”六大谜题全解析锐捷网络的全院零漫游方案是新一代医疗无线解决方案,专为智慧医院设计,通过零漫游主机和天线入室技术实现全院覆盖和移动零漫游体验。方案支持业务扩展全适配,优化运维管理,确保内外网物理隔离安全,并便捷部署物联网应用,帮助医院提升网络性能,支持旧设备利旧升级,降低成本。
-
#医疗
-
#医院网络
-
#无线
-
-
 精准出击!锐捷极简以太彩光网络4.0再添新翼,“超融合”方案创新而来
精准出击!锐捷极简以太彩光网络4.0再添新翼,“超融合”方案创新而来锐捷网络发布极简以太彩光4.0超融合方案,专为宿舍等高密接入场景设计。该方案采用统一以太网二层架构,弱电间无源部署,支持单核心接入超万间房间。创新推出有线无线一体化Wi-Fi 7面板型光无线接入点,实现灵活部署与统一运维,同时支持超聚合与超融合模式灵活适配,为高校及行业园区提供极简智能的全光网络解决方案。
-
#交换机
-
#全光网
-















