 发布时间:2025-09-12
发布时间:2025-09-12

2025年9月10日至12日,锐捷网络在深圳中国国际光电博览会(CIOE 2025)上以“算力·网络·互联”为主题,全面展示了在高速光互联与智算网络领域的一系列创新成果。包括首次对外公开的51.2T CPO交换机商用互联方案、全新推出的1.6T/800G光模块,以及新一代无损网络解决方案AI-FlexiForce的实机演示,系统呈现了公司从关键器件到整体解决方案的技术布局。

在本次光博会上,锐捷网络现场首次演示了基于共封装光学(CPO)技术的51.2T交换机商用互联方案,该方案以其超高集成度、显著能效提升和可维护性设计,能够很好地满足AI训练及超大规模计算集群对高速互联的持续增长需求,并为未来800G和1.6T网络升级提供了可行的技术路径。


锐捷51.2T CPO交换机采用博通Bailly 51.2Tbps CPO芯片,实现在4RU紧凑空间内提供128个400G FR4光交换端口,极大提升了设备端口密度与带宽容量。其最大技术亮点在于通过将光引擎与交换芯片共封装,显著缩短电互联路径,降低信号衰减与传输功耗。
该交换机还实现了系统级可维护性突破,兼容多个可现场更换的远程激光模块(RLM),解决了传统CPO技术中光引擎不可插拔的运维痛点。设备支持1+1冗余电源与7+1风扇冗余散热设计,保障了在高负荷智算场景下的连续稳定运行。此次展示中,该交换机在接近实际应用的场景中稳定运行,体现出CPO技术已初步具备商用部署能力。
此次展示的LPO光模块产品系列包括400G-Q112-DR4-L、800G-OSFP-DR8-L、800G-OSFP-2DR4-L及1.6T-OSFP-DR8-L等多个型号,全面覆盖从400G至1.6T的速率需求。所有型号激光器均采用硅光集成方案,显著提升器件一致性与整体性能。
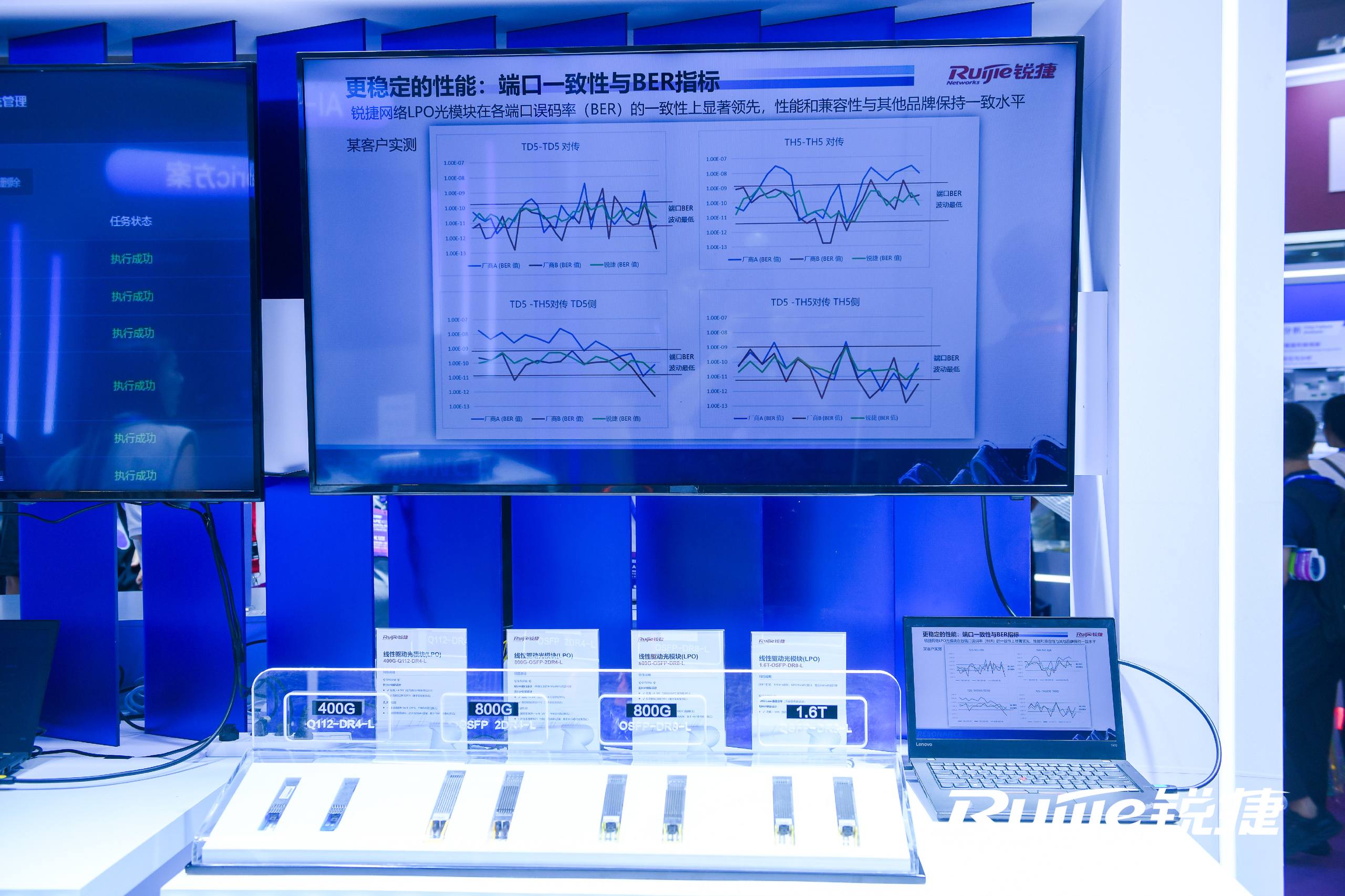

该系列模块彻底移除传统DSP芯片,经过多场景实测验证,在36支满负载业务环境下,使用LPO模块较DSP方案,整机功耗降低约21%,单模块功耗下降约38%。以8K卡集群为例,年电费可节省超过40万元,在提升能效的同时显著减少碳排放。
在延迟方面,LPO模块展现出优异性能,单端口端到端传输时延降低约50纳秒,四跳交换机互联场景下整体延迟减少近200纳秒,更好地满足AI训练/推理和高频交易等对时延极度敏感的应用需求。
可靠性成为此次新品的另一大亮点。借助硅光技术整合激光器与调制单元,大幅减少光学元件数量,从根本上降低了故障发生概率。模块更内置热敏电阻实时监测激光器温度,实现故障预警与精准定位,进一步提升了系统运维效率。
在本次展会上,锐捷网络新一代无损网络解决方案AI-FlexiForce备受瞩目。该方案围绕AI训练场景中高吞吐、低延迟、零丢包的严苛需求,从架构设计、流量调度、可靠性保障等多个维度实现突破,显著提升大规模AI集群的训练效率与稳定性。


AI-FlexiForce以DDC 2.0(Distributed Disaggregated Chassis)架构为核心,打破传统框式设备限制,实现真正开放解耦与弹性扩展。系统支持从数千至数万卡的大规模组网,单个集群两级组网9K*400G,多集群互联可达72K*400G,从容应对万亿参数大模型训练所需的通信规模。
方案创新采用基于Cell的信元交换与喷洒机制,取代传统逐流或逐包转发模式。通过在NCP节点完成Cell切片与重组,并结合端口到端口的VOQ与Credit主动调度机制,实现流量在Fabric内的无阻塞传输。面对AI训练中常见的长流拥塞与incast问题,AI-FlexiForce摒弃了传统PFC反压机制,通过主动式流控实现网络“先调度,再发送”,从根源上消除拥塞和PFC风暴。
在可靠性方面,系统提供七重高可用保障,涵盖端侧秒级逃生、链路亚毫秒收敛、设备级GR预处理隔离、LPO光链路增强等功能模块。尤其在使用LPO光模块后,光链路可靠性较传统DSP模块提升78%,进一步保障万卡集群中长时间训练任务的连续性。
AI-FlexiForce不仅提供了具备极致性能的无损网络环境,更通过开放架构与智能运维特性,为超大规模智算中心打造出高可靠、高效率、可持续演进的新一代网络底座。
在大会同期举办的“超万卡智算集群新型光技术发展论坛”上,锐捷网络光系统工程师刘敬伟发表了题为《AI场景下光互连技术路线及应用场景分析》的演讲,从技术演进、标准生态与场景适配等多个维度,深入解读了AI算力浪潮下光互联技术的发展方向。


刘敬伟博士指出:“全球部署的总AI算力每两年增长约100倍,单GPU算力、内存及电互联带宽的增长远无法匹配这一速度,光互连已成为突破带宽瓶颈的关键路径。”他进一步强调,在AI训练与推理集群中,低功耗、高密度、低时延和高可靠性是光互联系统的核心诉求。
他系统分析了线性驱动可插拔光学(LPO)、近封装光学(NPO)和共封装光学(CPO)三类技术路线的优势与挑战。LPO通过去除DSP芯片显著降低功耗和延迟,保留可插拔维护优势,已进入规模化商用元年,并依托MSA等产业标准生态逐步完善;NPO在光电间距、信号完整性与可维护性之间取得平衡,尤其适应国产化供应链需求;CPO则代表光电深度融合的终极形态,在能耗、集成度和延迟方面表现突出,尤其适合超高算力密度场景。
他强调,LPO、NPO、CPO并非互相替代,而是处于“代际重叠”的共存状态,未来将根据实际场景中成本、功耗、密度与可维护性的综合需求协同发展。
锐捷网络近年来不断加强对光通信领域的技术投入,围绕AI智算场景的核心需求,在高速光模块、先进互联技术与无损网络等领域取得多项突破。本次展会所展示的产品与方案,系统体现了公司从元件级到系统级的全面研发能力。
锐捷网络相关负责人表示:“AI应用迅速推进,对底层网络设施提出更高要求。我们将持续聚焦光通信技术创新,为超大规模智算中心提供高性能、低功耗的网络互联解决方案,助力中国AI产业稳健发展。”

 文档评价
文档评价




















